Compare commits
24 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| de877362c9 | |||
| 9b1254a6d9 | |||
| c110943f20 | |||
| e94eb11f63 | |||
| 0d498e3f44 | |||
| dd301dc422 | |||
| 9e6d90adfe | |||
| a6b688c976 | |||
| 10f1290ad9 | |||
| b51eefa139 | |||
| 805d7e3536 | |||
| 8f0472e8f5 | |||
| 002aa6a731 | |||
| 8a960389d1 | |||
| c7cd73ae1f | |||
| c8c1d0fd27 | |||
| c090979f3e | |||
| 3a4062c983 | |||
| bcf73c6e5c | |||
| 9cf5ce188a | |||
| a226309ce5 | |||
| 231f41e195 | |||
| 7c1546fb49 | |||
| b1dd2b55f8 |
171
README.md
171
README.md
@ -4,18 +4,18 @@
|
||||
|
||||
* Complete rewrite, cleaner object oriented code.
|
||||
* Python 3 and 2 support.
|
||||
* Installable via pip.
|
||||
* Installable via [pip](https://pypi.org/project/zfs-autobackup/).
|
||||
* Backwards compatible with your current backups and parameters.
|
||||
* Progressive thinning (via a destroy schedule. default schedule should be fine for most people)
|
||||
* Cleaner output, with optional color support (pip install colorama).
|
||||
* Clear distinction between local and remote output.
|
||||
* Summary at the beginning, displaying what will happen and the current thinning-schedule.
|
||||
* More effient destroying/skipping snaphots on the fly. (no more space issues if your backup is way behind)
|
||||
* More efficient destroying/skipping snapshots on the fly. (no more space issues if your backup is way behind)
|
||||
* Progress indicator (--progress)
|
||||
* Better property management (--set-properties and --filter-properties)
|
||||
* Better resume handling, automaticly abort invalid resumes.
|
||||
* Better resume handling, automatically abort invalid resumes.
|
||||
* More robust error handling.
|
||||
* Prepared for future enhanchements.
|
||||
* Prepared for future enhancements.
|
||||
* Supports raw backups for encryption.
|
||||
* Custom SSH client config.
|
||||
|
||||
@ -29,9 +29,9 @@ Other settings are just specified on the commandline. This also makes it easier
|
||||
|
||||
Since its using ZFS commands, you can see what its actually doing by specifying `--debug`. This also helps a lot if you run into some strange problem or error. You can just copy-paste the command that fails and play around with it on the commandline. (also something I missed in other tools)
|
||||
|
||||
An imporant feature thats missing from other tools is a reliable `--test` option: This allows you to see what zfs-autobackup will do and tune your parameters. It will do everything, except make changes to your zfs datasets.
|
||||
An important feature thats missing from other tools is a reliable `--test` option: This allows you to see what zfs-autobackup will do and tune your parameters. It will do everything, except make changes to your zfs datasets.
|
||||
|
||||
Another nice thing is progress reporting with `--progress`. Its very usefull with HUGE datasets, when you want to know how many hours/days it will take.
|
||||
Another nice thing is progress reporting with `--progress`. Its very useful with HUGE datasets, when you want to know how many hours/days it will take.
|
||||
|
||||
zfs-autobackup tries to be the easiest to use backup tool for zfs.
|
||||
|
||||
@ -64,12 +64,14 @@ zfs-autobackup tries to be the easiest to use backup tool for zfs.
|
||||
|
||||
### Using pip
|
||||
|
||||
The recommended way on most servers is to use pip:
|
||||
The recommended way on most servers is to use [pip](https://pypi.org/project/zfs-autobackup/):
|
||||
|
||||
```console
|
||||
[root@server ~]# pip install zfs-autobackup
|
||||
[root@server ~]# pip install --upgrade zfs-autobackup
|
||||
```
|
||||
|
||||
This can also be used to upgrade zfs-autobackup to the newest stable version.
|
||||
|
||||
### Using easy_install
|
||||
|
||||
On older servers you might have to use easy_install
|
||||
@ -82,7 +84,7 @@ On older servers you might have to use easy_install
|
||||
|
||||
Its also possible to just download <https://raw.githubusercontent.com/psy0rz/zfs_autobackup/master/bin/zfs-autobackup> and run it directly.
|
||||
|
||||
The only requirement that is sometimes missing is the `argparse` python module. Optionally you can install `colorma` for colors.
|
||||
The only requirement that is sometimes missing is the `argparse` python module. Optionally you can install `colorama` for colors.
|
||||
|
||||
It should work with python 2.7 and higher.
|
||||
|
||||
@ -165,7 +167,7 @@ rpool/swap autobackup:offsite1 true
|
||||
...
|
||||
```
|
||||
|
||||
Because we dont want to backup everything, we can exclude certain filesystem by setting the property to false:
|
||||
Because we don't want to backup everything, we can exclude certain filesystem by setting the property to false:
|
||||
|
||||
```console
|
||||
[root@pve ~]# zfs set autobackup:offsite1=false rpool/swap
|
||||
@ -182,7 +184,7 @@ rpool/swap autobackup:offsite1 false
|
||||
|
||||
### Running zfs-autobackup
|
||||
|
||||
Run the script on the backup server and pull the data from the server specfied by --ssh-source.
|
||||
Run the script on the backup server and pull the data from the server specified by --ssh-source.
|
||||
|
||||
```console
|
||||
[root@backup ~]# zfs-autobackup --ssh-source pve.server.com offsite1 backup/pve --progress --verbose
|
||||
@ -190,16 +192,16 @@ Run the script on the backup server and pull the data from the server specfied b
|
||||
#### Settings summary
|
||||
[Source] Datasets on: pve.server.com
|
||||
[Source] Keep the last 10 snapshots.
|
||||
[Source] Keep oldest of 1 day, delete after 1 week.
|
||||
[Source] Keep oldest of 1 week, delete after 1 month.
|
||||
[Source] Keep oldest of 1 month, delete after 1 year.
|
||||
[Source] Keep every 1 day, delete after 1 week.
|
||||
[Source] Keep every 1 week, delete after 1 month.
|
||||
[Source] Keep every 1 month, delete after 1 year.
|
||||
[Source] Send all datasets that have 'autobackup:offsite1=true' or 'autobackup:offsite1=child'
|
||||
|
||||
[Target] Datasets are local
|
||||
[Target] Keep the last 10 snapshots.
|
||||
[Target] Keep oldest of 1 day, delete after 1 week.
|
||||
[Target] Keep oldest of 1 week, delete after 1 month.
|
||||
[Target] Keep oldest of 1 month, delete after 1 year.
|
||||
[Target] Keep every 1 day, delete after 1 week.
|
||||
[Target] Keep every 1 week, delete after 1 month.
|
||||
[Target] Keep every 1 month, delete after 1 year.
|
||||
[Target] Receive datasets under: backup/pve
|
||||
|
||||
#### Selecting
|
||||
@ -233,18 +235,96 @@ Its also possible to let a server push its backup to the backup-server. However
|
||||
|
||||
### Automatic backups
|
||||
|
||||
Now everytime you run the command, zfs-autobackup will create a new snapshot and replicate your data.
|
||||
Now every time you run the command, zfs-autobackup will create a new snapshot and replicate your data.
|
||||
|
||||
Older snapshots will evertually be deleted, depending on the `--keep-source` and `--keep-target` settings. (The defaults are shown above under the 'Settings summary')
|
||||
Older snapshots will eventually be deleted, depending on the `--keep-source` and `--keep-target` settings. (The defaults are shown above under the 'Settings summary')
|
||||
|
||||
Once you've got the correct settings for your situation, you can just store the command in a cronjob.
|
||||
|
||||
Or just create a script and run it manually when you need it.
|
||||
|
||||
### Thinning out obsolete snapshots
|
||||
|
||||
The thinner is the thing that destroys old snapshots on the source and target.
|
||||
|
||||
The thinner operates "stateless": There is nothing in the name or properties of a snapshot that indicates how long it will be kept. Everytime zfs-autobackup runs, it will look at the timestamp of all the existing snapshots. From there it will determine which snapshots are obsolete according to your schedule. The advantage of this stateless system is that you can always change the schedule.
|
||||
|
||||
Note that the thinner will ONLY destroy snapshots that are matching the naming pattern of zfs-autobackup. If you use `--other-snapshots`, it wont destroy those snapshots after replicating them to the target.
|
||||
|
||||
#### Thinning schedule
|
||||
|
||||
The default thinning schedule is: `10,1d1w,1w1m,1m1y`.
|
||||
|
||||
The schedule consists of multiple rules separated by a `,`
|
||||
|
||||
A plain number specifies how many snapshots you want to always keep, regardless of time or interval.
|
||||
|
||||
The format of the other rules is: `<Interval><TTL>`.
|
||||
|
||||
* Interval: The minimum interval between the snapshots. Snapshots with intervals smaller than this will be destroyed.
|
||||
* TTL: The maximum time to life time of a snapshot, after that they will be destroyed.
|
||||
* These are the time units you can use for interval and TTL:
|
||||
* `y`: Years
|
||||
* `m`: Months
|
||||
* `d`: Days
|
||||
* `h`: Hours
|
||||
* `min`: Minutes
|
||||
* `s`: Seconds
|
||||
|
||||
Since this might sound very complicated, the `--verbose` option will show you what it all means:
|
||||
|
||||
```console
|
||||
[Source] Keep the last 10 snapshots.
|
||||
[Source] Keep every 1 day, delete after 1 week.
|
||||
[Source] Keep every 1 week, delete after 1 month.
|
||||
[Source] Keep every 1 month, delete after 1 year.
|
||||
```
|
||||
|
||||
A snapshot will only be destroyed if it not needed anymore by ANY of the rules.
|
||||
|
||||
You can specify as many rules as you need. The order of the rules doesn't matter.
|
||||
|
||||
Keep in mind its up to you to actually run zfs-autobackup often enough: If you want to keep hourly snapshots, you have to make sure you at least run it every hour.
|
||||
|
||||
However, its no problem if you run it more or less often than that: The thinner will still do its best to choose an optimal set of snapshots to choose.
|
||||
|
||||
If you want to keep as few snapshots as possible, just specify 0. (`--keep-source=0` for example)
|
||||
|
||||
If you want to keep ALL the snapshots, just specify a very high number.
|
||||
|
||||
#### More details about the Thinner
|
||||
|
||||
We will give a practical example of how the thinner operates.
|
||||
|
||||
Say we want have 3 thinner rules:
|
||||
|
||||
* We want to keep daily snapshots for 7 days.
|
||||
* We want to keep weekly snapshots for 4 weeks.
|
||||
* We want to keep monthly snapshots for 12 months.
|
||||
|
||||
So far we have taken 4 snapshots at random moments:
|
||||
|
||||
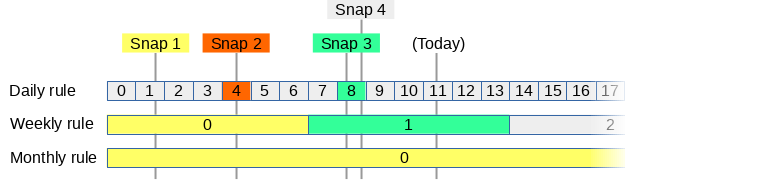
|
||||
|
||||
For every rule, the thinner will divide the timeline in blocks and assign each snapshot to a block.
|
||||
|
||||
A block can only be assigned one snapshot: If multiple snapshots fall into the same block, it only assigns it to the oldest that we want to keep.
|
||||
|
||||
The colors show to which block a snapshot belongs:
|
||||
|
||||
* Snapshot 1: This snapshot belongs to daily block 1, weekly block 0 and monthly block 0. However the daily block is too old.
|
||||
* Snapshot 2: Since weekly block 0 and monthly block 0 already have a snapshot, it only belongs to daily block 4.
|
||||
* Snapshot 3: This snapshot belongs to daily block 8 and weekly block 1.
|
||||
* Snapshot 4: Since daily block 8 already has a snapshot, this one doesn't belong to anything and can be deleted right away. (it will be keeped for now since its the last snapshot)
|
||||
|
||||
zfs-autobackup will re-evaluate this on every run: As soon as a snapshot doesn't belong to any block anymore it will be destroyed.
|
||||
|
||||
Snapshots on the source that still have to be send to the target wont be destroyed off course. (If the target still wants them, according to the target schedule)
|
||||
|
||||
## Tips
|
||||
|
||||
* Use ```--debug``` if something goes wrong and you want to see the commands that are executed. This will also stop at the first error.
|
||||
* You can split up the snapshotting and sending tasks by creating two cronjobs. Use ```--no-send``` for the snapshotter-cronjob and use ```--no-snapshot``` for the send-cronjob. This is usefull if you only want to send at night or if your send take too long.
|
||||
* You can split up the snapshotting and sending tasks by creating two cronjobs. Use ```--no-send``` for the snapshotter-cronjob and use ```--no-snapshot``` for the send-cronjob. This is useful if you only want to send at night or if your send take too long.
|
||||
* Set the ```readonly``` property of the target filesystem to ```on```. This prevents changes on the target side. (Normally, if there are changes the next backup will fail and will require a zfs rollback.) Note that readonly means you cant change the CONTENTS of the dataset directly. Its still possible to receive new datasets and manipulate properties etc.
|
||||
* Use ```--clear-refreservation``` to save space on your backup server.
|
||||
* Use ```--clear-mountpoint``` to prevent the target server from mounting the backupped filesystem in the wrong place during a reboot.
|
||||
@ -292,17 +372,18 @@ Here you find all the options:
|
||||
usage: zfs-autobackup [-h] [--ssh-config SSH_CONFIG] [--ssh-source SSH_SOURCE]
|
||||
[--ssh-target SSH_TARGET] [--keep-source KEEP_SOURCE]
|
||||
[--keep-target KEEP_TARGET] [--other-snapshots]
|
||||
[--no-snapshot] [--no-send] [--allow-empty]
|
||||
[--ignore-replicated] [--no-holds] [--resume]
|
||||
[--strip-path STRIP_PATH] [--clear-refreservation]
|
||||
[--clear-mountpoint]
|
||||
[--no-snapshot] [--no-send] [--min-change MIN_CHANGE]
|
||||
[--allow-empty] [--ignore-replicated] [--no-holds]
|
||||
[--resume] [--strip-path STRIP_PATH]
|
||||
[--clear-refreservation] [--clear-mountpoint]
|
||||
[--filter-properties FILTER_PROPERTIES]
|
||||
[--set-properties SET_PROPERTIES] [--rollback]
|
||||
[--ignore-transfer-errors] [--raw] [--test] [--verbose]
|
||||
[--debug] [--debug-output] [--progress]
|
||||
[--destroy-incompatible] [--ignore-transfer-errors]
|
||||
[--raw] [--test] [--verbose] [--debug] [--debug-output]
|
||||
[--progress]
|
||||
backup_name target_path
|
||||
|
||||
zfs-autobackup v3.0-rc6 - Copyright 2020 E.H.Eefting (edwin@datux.nl)
|
||||
zfs-autobackup v3.0-rc8 - Copyright 2020 E.H.Eefting (edwin@datux.nl)
|
||||
|
||||
positional arguments:
|
||||
backup_name Name of the backup (you should set the zfs property
|
||||
@ -328,15 +409,19 @@ optional arguments:
|
||||
10,1d1w,1w1m,1m1y
|
||||
--other-snapshots Send over other snapshots as well, not just the ones
|
||||
created by this tool.
|
||||
--no-snapshot Dont create new snapshots (usefull for finishing
|
||||
--no-snapshot Dont create new snapshots (useful for finishing
|
||||
uncompleted backups, or cleanups)
|
||||
--no-send Dont send snapshots (usefull for cleanups, or if you
|
||||
want a serperate send-cronjob)
|
||||
--no-send Dont send snapshots (useful for cleanups, or if you
|
||||
want a separate send-cronjob)
|
||||
--min-change MIN_CHANGE
|
||||
Number of bytes written after which we consider a
|
||||
dataset changed (default 1)
|
||||
--allow-empty If nothing has changed, still create empty snapshots.
|
||||
(same as --min-change=0)
|
||||
--ignore-replicated Ignore datasets that seem to be replicated some other
|
||||
way. (No changes since lastest snapshot. Usefull for
|
||||
way. (No changes since lastest snapshot. Useful for
|
||||
proxmox HA replication)
|
||||
--no-holds Dont lock snapshots on the source. (Usefull to allow
|
||||
--no-holds Dont lock snapshots on the source. (Useful to allow
|
||||
proxmox HA replication to switches nodes)
|
||||
--resume Support resuming of interrupted transfers by using the
|
||||
zfs extensible_dataset feature (both zpools should
|
||||
@ -354,19 +439,22 @@ optional arguments:
|
||||
(recommended, prevents mount conflicts. same as --set-
|
||||
properties canmount=noauto)
|
||||
--filter-properties FILTER_PROPERTIES
|
||||
List of propererties to "filter" when receiving
|
||||
List of properties to "filter" when receiving
|
||||
filesystems. (you can still restore them with zfs
|
||||
inherit -S)
|
||||
--set-properties SET_PROPERTIES
|
||||
List of propererties to override when receiving
|
||||
List of properties to override when receiving
|
||||
filesystems. (you can still restore them with zfs
|
||||
inherit -S)
|
||||
--rollback Rollback changes on the target before starting a
|
||||
backup. (normally you can prevent changes by setting
|
||||
--rollback Rollback changes to the latest target snapshot before
|
||||
starting. (normally you can prevent changes by setting
|
||||
the readonly property on the target_path to on)
|
||||
--destroy-incompatible
|
||||
Destroy incompatible snapshots on target. Use with
|
||||
care! (implies --rollback)
|
||||
--ignore-transfer-errors
|
||||
Ignore transfer errors (still checks if received
|
||||
filesystem exists. usefull for acltype errors)
|
||||
filesystem exists. useful for acltype errors)
|
||||
--raw For encrypted datasets, send data exactly as it exists
|
||||
on disk.
|
||||
--test dont change anything, just show what would be done
|
||||
@ -391,7 +479,7 @@ You forgot to setup automatic login via SSH keys, look in the example how to do
|
||||
|
||||
This usually means you've created a new snapshot on the target side during a backup:
|
||||
|
||||
* Solution 1: Restart zfs-autobackup and make sure you dont use --resume. If you did use --resume, be sure to "abort" the recveive on the target side with zfs recv -A.
|
||||
* Solution 1: Restart zfs-autobackup and make sure you don't use --resume. If you did use --resume, be sure to "abort" the receive on the target side with zfs recv -A.
|
||||
* Solution 2: Destroy the newly created snapshot and restart zfs-autobackup.
|
||||
|
||||
### It says 'internal error: Invalid argument'
|
||||
@ -420,13 +508,13 @@ Put this command directly after the zfs_backup command in your cronjob:
|
||||
zabbix-job-status backup_smartos01_fs1 daily $?
|
||||
```
|
||||
|
||||
This will update the zabbix server with the exitcode and will also alert you if the job didnt run for more than 2 days.
|
||||
This will update the zabbix server with the exit code and will also alert you if the job didn't run for more than 2 days.
|
||||
|
||||
## Backuping up a proxmox cluster with HA replication
|
||||
|
||||
Due to the nature of proxmox we had to make a few enhancements to zfs-autobackup. This will probably also benefit other systems that use their own replication in combination with zfs-autobackup.
|
||||
|
||||
All data under rpool/data can be on multiple nodes of the cluster. The naming of those filesystem is unique over the whole cluster. Because of this we should backup rpool/data of all nodes to the same destination. This way we wont have duplicate backups of the filesystems that are replicated. Because of various options, you can even migrate hosts and zfs-autobackup will be fine. (and it will get the next backup from the new node automaticly)
|
||||
All data under rpool/data can be on multiple nodes of the cluster. The naming of those filesystem is unique over the whole cluster. Because of this we should backup rpool/data of all nodes to the same destination. This way we wont have duplicate backups of the filesystems that are replicated. Because of various options, you can even migrate hosts and zfs-autobackup will be fine. (and it will get the next backup from the new node automatically)
|
||||
|
||||
In the example below we have 3 nodes, named h4, h5 and h6.
|
||||
|
||||
@ -452,6 +540,7 @@ Extra options needed for proxmox with HA:
|
||||
|
||||
* --no-holds: To allow proxmox to destroy our snapshots if a VM migrates to another node.
|
||||
* --ignore-replicated: To ignore the replicated filesystems of proxmox on the receiving proxmox nodes. (e.g: only backup from the node where the VM is active)
|
||||
* --min-change 200000: Ignore replicated works by checking if there are no changes since the last snapshot. However for some reason proxmox always has some small changes. (Probably house-keeping data are something? This always was fine and suddenly changed with an update)
|
||||
|
||||
I use the following backup script on the backup server:
|
||||
|
||||
@ -459,7 +548,7 @@ I use the following backup script on the backup server:
|
||||
for H in h4 h5 h6; do
|
||||
echo "################################### DATA $H"
|
||||
#backup data filesystems to a common place
|
||||
./zfs-autobackup --ssh-source root@$H data_smartos03 zones/backup/zfsbackups/pxe1_data --clear-refreservation --clear-mountpoint --ignore-transfer-errors --strip-path 2 --verbose --resume --ignore-replicated --no-holds $@
|
||||
./zfs-autobackup --ssh-source root@$H data_smartos03 zones/backup/zfsbackups/pxe1_data --clear-refreservation --clear-mountpoint --ignore-transfer-errors --strip-path 2 --verbose --resume --ignore-replicated --min-change 200000 --no-holds $@
|
||||
zabbix-job-status backup_$H""_data_smartos03 daily $? >/dev/null 2>/dev/null
|
||||
|
||||
echo "################################### RPOOL $H"
|
||||
|
||||
@ -26,7 +26,7 @@ if sys.stdout.isatty():
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
VERSION="3.0-rc7"
|
||||
VERSION="3.0-rc10"
|
||||
HEADER="zfs-autobackup v{} - Copyright 2020 E.H.Eefting (edwin@datux.nl)\n".format(VERSION)
|
||||
|
||||
class Log:
|
||||
@ -40,6 +40,7 @@ class Log:
|
||||
print(colorama.Fore.RED+colorama.Style.BRIGHT+ "! "+txt+colorama.Style.RESET_ALL, file=sys.stderr)
|
||||
else:
|
||||
print("! "+txt, file=sys.stderr)
|
||||
sys.stderr.flush()
|
||||
|
||||
def verbose(self, txt):
|
||||
if self.show_verbose:
|
||||
@ -47,6 +48,7 @@ class Log:
|
||||
print(colorama.Style.NORMAL+ " "+txt+colorama.Style.RESET_ALL)
|
||||
else:
|
||||
print(" "+txt)
|
||||
sys.stdout.flush()
|
||||
|
||||
def debug(self, txt):
|
||||
if self.show_debug:
|
||||
@ -54,6 +56,7 @@ class Log:
|
||||
print(colorama.Fore.GREEN+ "# "+txt+colorama.Style.RESET_ALL)
|
||||
else:
|
||||
print("# "+txt)
|
||||
sys.stdout.flush()
|
||||
|
||||
|
||||
|
||||
@ -117,7 +120,7 @@ class ThinnerRule:
|
||||
|
||||
self.rule_str=rule_str
|
||||
|
||||
self.human_str="Keep oldest of {} {}{}, delete after {} {}{}.".format(
|
||||
self.human_str="Keep every {} {}{}, delete after {} {}{}.".format(
|
||||
period_amount, self.TIME_DESC[period_unit], period_amount!=1 and "s" or "", ttl_amount, self.TIME_DESC[ttl_unit], ttl_amount!=1 and "s" or "" )
|
||||
|
||||
|
||||
@ -171,7 +174,6 @@ class Thinner:
|
||||
objects: list of objects to thin. every object should have timestamp attribute.
|
||||
keep_objects: objects to always keep (these should also be in normal objects list, so we can use them to perhaps delete other obsolete objects)
|
||||
|
||||
|
||||
return( keeps, removes )
|
||||
"""
|
||||
|
||||
@ -309,7 +311,7 @@ class ExecuteNode:
|
||||
def __init__(self, ssh_config=None, ssh_to=None, readonly=False, debug_output=False):
|
||||
"""ssh_config: custom ssh config
|
||||
ssh_to: server you want to ssh to. none means local
|
||||
readonly: only execute commands that dont make any changes (usefull for testing-runs)
|
||||
readonly: only execute commands that don't make any changes (useful for testing-runs)
|
||||
debug_output: show output and exit codes of commands in debugging output.
|
||||
"""
|
||||
|
||||
@ -348,7 +350,7 @@ class ExecuteNode:
|
||||
def run(self, cmd, input=None, tab_split=False, valid_exitcodes=[ 0 ], readonly=False, hide_errors=False, pipe=False, return_stderr=False):
|
||||
"""run a command on the node
|
||||
|
||||
readonly: make this True if the command doesnt make any changes and is safe to execute in testmode
|
||||
readonly: make this True if the command doesn't make any changes and is safe to execute in testmode
|
||||
pipe: Instead of executing, return a pipe-handle to be used to input to another run() command. (just like a | in linux)
|
||||
input: Can be None, a string or a pipe-handle you got from another run()
|
||||
return_stderr: return both stdout and stderr as a tuple
|
||||
@ -366,9 +368,9 @@ class ExecuteNode:
|
||||
encoded_cmd.append(self.ssh_to.encode('utf-8'))
|
||||
|
||||
#make sure the command gets all the data in utf8 format:
|
||||
#(this is neccesary if LC_ALL=en_US.utf8 is not set in the environment)
|
||||
#(this is necessary if LC_ALL=en_US.utf8 is not set in the environment)
|
||||
for arg in cmd:
|
||||
#add single quotes for remote commands to support spaces and other wierd stuff (remote commands are executed in a shell)
|
||||
#add single quotes for remote commands to support spaces and other weird stuff (remote commands are executed in a shell)
|
||||
encoded_cmd.append( ("'"+arg+"'").encode('utf-8'))
|
||||
|
||||
else:
|
||||
@ -487,7 +489,7 @@ class ExecuteNode:
|
||||
|
||||
class ZfsDataset():
|
||||
"""a zfs dataset (filesystem/volume/snapshot/clone)
|
||||
Note that a dataset doesnt have to actually exist (yet/anymore)
|
||||
Note that a dataset doesn't have to actually exist (yet/anymore)
|
||||
Also most properties are cached for performance-reasons, but also to allow --test to function correctly.
|
||||
|
||||
"""
|
||||
@ -501,7 +503,7 @@ class ZfsDataset():
|
||||
|
||||
def __init__(self, zfs_node, name, force_exists=None):
|
||||
"""name: full path of the zfs dataset
|
||||
exists: specifiy if you already know a dataset exists or not. for performance reasons. (othewise it will have to check with zfs list when needed)
|
||||
exists: specify if you already know a dataset exists or not. for performance reasons. (otherwise it will have to check with zfs list when needed)
|
||||
"""
|
||||
self.zfs_node=zfs_node
|
||||
self.name=name #full name
|
||||
@ -590,7 +592,7 @@ class ZfsDataset():
|
||||
|
||||
|
||||
def find_prev_snapshot(self, snapshot, other_snapshots=False):
|
||||
"""find previous snapshot in this dataset. None if it doesnt exist.
|
||||
"""find previous snapshot in this dataset. None if it doesn't exist.
|
||||
|
||||
other_snapshots: set to true to also return snapshots that where not created by us. (is_ours)
|
||||
"""
|
||||
@ -607,7 +609,7 @@ class ZfsDataset():
|
||||
|
||||
|
||||
def find_next_snapshot(self, snapshot, other_snapshots=False):
|
||||
"""find next snapshot in this dataset. None if it doesnt exist"""
|
||||
"""find next snapshot in this dataset. None if it doesn't exist"""
|
||||
|
||||
if self.is_snapshot:
|
||||
raise(Exception("Please call this on a dataset."))
|
||||
@ -623,7 +625,7 @@ class ZfsDataset():
|
||||
@cached_property
|
||||
def exists(self):
|
||||
"""check if dataset exists.
|
||||
Use force to force a specific value to be cached, if you already know. Usefull for performance reasons"""
|
||||
Use force to force a specific value to be cached, if you already know. Useful for performance reasons"""
|
||||
|
||||
|
||||
if self.force_exists!=None:
|
||||
@ -637,7 +639,7 @@ class ZfsDataset():
|
||||
|
||||
|
||||
def create_filesystem(self, parents=False):
|
||||
"""create a filesytem"""
|
||||
"""create a filesystem"""
|
||||
if parents:
|
||||
self.verbose("Creating filesystem and parents")
|
||||
self.zfs_node.run(["zfs", "create", "-p", self.name ])
|
||||
@ -704,7 +706,7 @@ class ZfsDataset():
|
||||
|
||||
|
||||
def is_ours(self):
|
||||
"""return true if this snapshot is created by this backup_nanme"""
|
||||
"""return true if this snapshot is created by this backup_name"""
|
||||
if re.match("^"+self.zfs_node.backup_name+"-[0-9]*$", self.snapshot_name):
|
||||
return(True)
|
||||
else:
|
||||
@ -867,7 +869,7 @@ class ZfsDataset():
|
||||
"""returns a pipe with zfs send output for this snapshot
|
||||
|
||||
resume: Use resuming (both sides need to support it)
|
||||
resume_token: resume sending from this token. (in that case we dont need to know snapshot names)
|
||||
resume_token: resume sending from this token. (in that case we don't need to know snapshot names)
|
||||
|
||||
"""
|
||||
#### build source command
|
||||
@ -893,7 +895,7 @@ class ZfsDataset():
|
||||
cmd.append("-P")
|
||||
|
||||
|
||||
#resume a previous send? (dont need more parameters in that case)
|
||||
#resume a previous send? (don't need more parameters in that case)
|
||||
if resume_token:
|
||||
cmd.extend([ "-t", resume_token ])
|
||||
|
||||
@ -911,7 +913,7 @@ class ZfsDataset():
|
||||
# if args.buffer and args.ssh_source!="local":
|
||||
# cmd.append("|mbuffer -m {}".format(args.buffer))
|
||||
|
||||
#NOTE: this doenst start the send yet, it only returns a subprocess.Pipe
|
||||
#NOTE: this doesn't start the send yet, it only returns a subprocess.Pipe
|
||||
return(self.zfs_node.run(cmd, pipe=True))
|
||||
|
||||
|
||||
@ -926,7 +928,7 @@ class ZfsDataset():
|
||||
|
||||
cmd.extend(["zfs", "recv"])
|
||||
|
||||
#dont mount filesystem that is received
|
||||
#don't mount filesystem that is received
|
||||
cmd.append("-u")
|
||||
|
||||
for property in filter_properties:
|
||||
@ -961,7 +963,8 @@ class ZfsDataset():
|
||||
|
||||
#check if transfer was really ok (exit codes have been wrong before due to bugs in zfs-utils and can be ignored by some parameters)
|
||||
if not self.exists:
|
||||
raise(Exception("Target doesnt exist after transfer, something went wrong."))
|
||||
self.error("error during transfer")
|
||||
raise(Exception("Target doesn't exist after transfer, something went wrong."))
|
||||
|
||||
# if args.buffer and args.ssh_target!="local":
|
||||
# cmd.append("|mbuffer -m {}".format(args.buffer))
|
||||
@ -982,7 +985,7 @@ class ZfsDataset():
|
||||
if not prev_snapshot:
|
||||
target_snapshot.verbose("receiving full".format(self.snapshot_name))
|
||||
else:
|
||||
#incemental
|
||||
#incremental
|
||||
target_snapshot.verbose("receiving incremental".format(self.snapshot_name))
|
||||
|
||||
#do it
|
||||
@ -995,9 +998,13 @@ class ZfsDataset():
|
||||
|
||||
|
||||
def rollback(self):
|
||||
"""rollback to this snapshot"""
|
||||
"""rollback to latest existing snapshot on this dataset"""
|
||||
self.debug("Rolling back")
|
||||
self.zfs_node.run(["zfs", "rollback", self.name])
|
||||
|
||||
for snapshot in reversed(self.snapshots):
|
||||
if snapshot.exists:
|
||||
self.zfs_node.run(["zfs", "rollback", snapshot.name])
|
||||
return
|
||||
|
||||
|
||||
def get_resume_snapshot(self, resume_token):
|
||||
@ -1020,19 +1027,30 @@ class ZfsDataset():
|
||||
return(None)
|
||||
|
||||
|
||||
|
||||
|
||||
def thin(self, keeps=[]):
|
||||
def thin_list(self, keeps=[], ignores=[]):
|
||||
"""determines list of snapshots that should be kept or deleted based on the thinning schedule. cull the herd!
|
||||
keep: list of snapshots to always keep (usually the last)
|
||||
ignores: snapshots to completely ignore (usually incompatible target snapshots that are going to be destroyed anyway)
|
||||
|
||||
returns: ( keeps, obsoletes )
|
||||
"""
|
||||
return(self.zfs_node.thinner.thin(self.our_snapshots, keep_objects=keeps))
|
||||
|
||||
snapshots=[snapshot for snapshot in self.our_snapshots if snapshot not in ignores]
|
||||
|
||||
return(self.zfs_node.thinner.thin(snapshots, keep_objects=keeps))
|
||||
|
||||
|
||||
def thin(self):
|
||||
"""destroys snapshots according to thin_list, except last snapshot"""
|
||||
|
||||
(keeps, obsoletes)=self.thin_list(keeps=self.our_snapshots[-1:])
|
||||
for obsolete in obsoletes:
|
||||
obsolete.destroy()
|
||||
self.snapshots.remove(obsolete)
|
||||
|
||||
|
||||
def find_common_snapshot(self, target_dataset):
|
||||
"""find latest coommon snapshot between us and target
|
||||
"""find latest common snapshot between us and target
|
||||
returns None if its an initial transfer
|
||||
"""
|
||||
if not target_dataset.snapshots:
|
||||
@ -1043,16 +1061,48 @@ class ZfsDataset():
|
||||
|
||||
# if not snapshot:
|
||||
#try to common snapshot
|
||||
for target_snapshot in reversed(target_dataset.snapshots):
|
||||
if self.find_snapshot(target_snapshot):
|
||||
target_snapshot.debug("common snapshot")
|
||||
return(target_snapshot)
|
||||
# target_snapshot.error("Latest common snapshot, roll back to this.")
|
||||
# raise(Exception("Cant find latest target snapshot on source."))
|
||||
target_dataset.error("Cant find common snapshot with target. ")
|
||||
raise(Exception("You probablly need to delete the target dataset to fix this."))
|
||||
for source_snapshot in reversed(self.snapshots):
|
||||
if target_dataset.find_snapshot(source_snapshot):
|
||||
source_snapshot.debug("common snapshot")
|
||||
return(source_snapshot)
|
||||
target_dataset.error("Cant find common snapshot with source.")
|
||||
raise(Exception("You probably need to delete the target dataset to fix this."))
|
||||
|
||||
|
||||
def find_start_snapshot(self, common_snapshot, other_snapshots):
|
||||
"""finds first snapshot to send"""
|
||||
|
||||
if not common_snapshot:
|
||||
if not self.snapshots:
|
||||
start_snapshot=None
|
||||
else:
|
||||
#start from beginning
|
||||
start_snapshot=self.snapshots[0]
|
||||
|
||||
if not start_snapshot.is_ours() and not other_snapshots:
|
||||
# try to start at a snapshot thats ours
|
||||
start_snapshot=self.find_next_snapshot(start_snapshot, other_snapshots)
|
||||
else:
|
||||
start_snapshot=self.find_next_snapshot(common_snapshot, other_snapshots)
|
||||
|
||||
return(start_snapshot)
|
||||
|
||||
|
||||
def find_incompatible_snapshots(self, common_snapshot):
|
||||
"""returns a list of snapshots that is incompatible for a zfs recv onto the common_snapshot.
|
||||
all direct followup snapshots with written=0 are compatible."""
|
||||
|
||||
ret=[]
|
||||
|
||||
if common_snapshot and self.snapshots:
|
||||
followup=True
|
||||
for snapshot in self.snapshots[self.find_snapshot_index(common_snapshot)+1:]:
|
||||
if not followup or int(snapshot.properties['written'])!=0:
|
||||
followup=False
|
||||
ret.append(snapshot)
|
||||
|
||||
return(ret)
|
||||
|
||||
|
||||
def get_allowed_properties(self, filter_properties, set_properties):
|
||||
"""only returns lists of allowed properties for this dataset type"""
|
||||
@ -1072,26 +1122,17 @@ class ZfsDataset():
|
||||
return ( ( allowed_filter_properties, allowed_set_properties ) )
|
||||
|
||||
|
||||
def sync_snapshots(self, target_dataset, show_progress=False, resume=True, filter_properties=[], set_properties=[], ignore_recv_exit_code=False, source_holds=True, rollback=False, raw=False, other_snapshots=False, no_send=False):
|
||||
|
||||
|
||||
def sync_snapshots(self, target_dataset, show_progress=False, resume=True, filter_properties=[], set_properties=[], ignore_recv_exit_code=False, source_holds=True, rollback=False, raw=False, other_snapshots=False, no_send=False, destroy_incompatible=False):
|
||||
"""sync this dataset's snapshots to target_dataset, while also thinning out old snapshots along the way."""
|
||||
|
||||
#determine start snapshot (the first snapshot after the common snapshot)
|
||||
#determine common and start snapshot
|
||||
target_dataset.debug("Determining start snapshot")
|
||||
common_snapshot=self.find_common_snapshot(target_dataset)
|
||||
|
||||
if not common_snapshot:
|
||||
if not self.snapshots:
|
||||
start_snapshot=None
|
||||
else:
|
||||
#start from beginning
|
||||
start_snapshot=self.snapshots[0]
|
||||
|
||||
if not start_snapshot.is_ours() and not other_snapshots:
|
||||
# try to start at a snapshot thats ours
|
||||
start_snapshot=self.find_next_snapshot(start_snapshot, other_snapshots)
|
||||
else:
|
||||
start_snapshot=self.find_next_snapshot(common_snapshot, other_snapshots)
|
||||
|
||||
start_snapshot=self.find_start_snapshot(common_snapshot, other_snapshots)
|
||||
#should be destroyed before attempting zfs recv:
|
||||
incompatible_target_snapshots=target_dataset.find_incompatible_snapshots(common_snapshot)
|
||||
|
||||
#make target snapshot list the same as source, by adding virtual non-existing ones to the list.
|
||||
target_dataset.debug("Creating virtual target snapshots")
|
||||
@ -1106,33 +1147,33 @@ class ZfsDataset():
|
||||
#now let thinner decide what we want on both sides as final state (after all transfers are done)
|
||||
self.debug("Create thinning list")
|
||||
if self.our_snapshots:
|
||||
(source_keeps, source_obsoletes)=self.thin(keeps=[self.our_snapshots[-1]])
|
||||
(source_keeps, source_obsoletes)=self.thin_list(keeps=[self.our_snapshots[-1]])
|
||||
else:
|
||||
source_keeps=[]
|
||||
source_obsoletes=[]
|
||||
|
||||
if target_dataset.our_snapshots:
|
||||
(target_keeps, target_obsoletes)=target_dataset.thin(keeps=[target_dataset.our_snapshots[-1]])
|
||||
(target_keeps, target_obsoletes)=target_dataset.thin_list(keeps=[target_dataset.our_snapshots[-1]], ignores=incompatible_target_snapshots)
|
||||
else:
|
||||
target_keeps=[]
|
||||
target_obsoletes=[]
|
||||
|
||||
|
||||
#on source: destroy all obsoletes before common. but after common only delete snapshots that are obsolete on both sides.
|
||||
#on source: destroy all obsoletes before common. but after common, only delete snapshots that target also doesn't want to explicitly keep
|
||||
before_common=True
|
||||
for source_snapshot in self.snapshots:
|
||||
if not common_snapshot or source_snapshot.snapshot_name==common_snapshot.snapshot_name:
|
||||
if common_snapshot and source_snapshot.snapshot_name==common_snapshot.snapshot_name:
|
||||
before_common=False
|
||||
#never destroy common snapshot
|
||||
else:
|
||||
target_snapshot=target_dataset.find_snapshot(source_snapshot)
|
||||
if (source_snapshot in source_obsoletes) and (before_common or (target_snapshot in target_obsoletes)):
|
||||
if (source_snapshot in source_obsoletes) and (before_common or (target_snapshot not in target_keeps)):
|
||||
source_snapshot.destroy()
|
||||
|
||||
|
||||
#on target: destroy everything thats obsolete, except common_snapshot
|
||||
for target_snapshot in target_dataset.snapshots:
|
||||
if (not common_snapshot or target_snapshot.snapshot_name!=common_snapshot.snapshot_name) and (target_snapshot in target_obsoletes):
|
||||
if (target_snapshot in target_obsoletes) and (not common_snapshot or target_snapshot.snapshot_name!=common_snapshot.snapshot_name):
|
||||
if target_snapshot.exists:
|
||||
target_snapshot.destroy()
|
||||
|
||||
@ -1142,7 +1183,7 @@ class ZfsDataset():
|
||||
return
|
||||
|
||||
|
||||
#resume?
|
||||
#resume?
|
||||
resume_token=None
|
||||
if 'receive_resume_token' in target_dataset.properties:
|
||||
resume_token=target_dataset.properties['receive_resume_token']
|
||||
@ -1154,12 +1195,25 @@ class ZfsDataset():
|
||||
resume_token=None
|
||||
|
||||
|
||||
#roll target back to common snapshot on target?
|
||||
if common_snapshot and rollback:
|
||||
target_dataset.find_snapshot(common_snapshot).rollback()
|
||||
#incompatible target snapshots?
|
||||
if incompatible_target_snapshots:
|
||||
if not destroy_incompatible:
|
||||
for snapshot in incompatible_target_snapshots:
|
||||
snapshot.error("Incompatible snapshot")
|
||||
raise(Exception("Please destroy incompatible snapshots or use --destroy-incompatible."))
|
||||
else:
|
||||
for snapshot in incompatible_target_snapshots:
|
||||
snapshot.verbose("Incompatible snapshot")
|
||||
snapshot.destroy()
|
||||
target_dataset.snapshots.remove(snapshot)
|
||||
|
||||
|
||||
#now actually the snapshots
|
||||
#rollback target to latest?
|
||||
if rollback:
|
||||
target_dataset.rollback()
|
||||
|
||||
|
||||
#now actually transfer the snapshots
|
||||
prev_source_snapshot=common_snapshot
|
||||
source_snapshot=start_snapshot
|
||||
while source_snapshot:
|
||||
@ -1182,19 +1236,19 @@ class ZfsDataset():
|
||||
|
||||
# we may now destroy the previous source snapshot if its obsolete
|
||||
if prev_source_snapshot in source_obsoletes:
|
||||
prev_source_snapshot.destroy()
|
||||
prev_source_snapshot.destroy()
|
||||
|
||||
# destroy the previous target snapshot if obsolete (usually this is only the common_snapshot, the rest was already destroyed or will not be send)
|
||||
prev_target_snapshot=target_dataset.find_snapshot(common_snapshot)
|
||||
prev_target_snapshot=target_dataset.find_snapshot(prev_source_snapshot)
|
||||
if prev_target_snapshot in target_obsoletes:
|
||||
prev_target_snapshot.destroy()
|
||||
|
||||
prev_source_snapshot=source_snapshot
|
||||
else:
|
||||
source_snapshot.debug("skipped (target doesnt need it)")
|
||||
source_snapshot.debug("skipped (target doesn't need it)")
|
||||
#was it actually a resume?
|
||||
if resume_token:
|
||||
target_dataset.debug("aborting resume, since we dont want that snapshot anymore")
|
||||
target_dataset.debug("aborting resume, since we don't want that snapshot anymore")
|
||||
target_dataset.abort_resume()
|
||||
resume_token=None
|
||||
|
||||
@ -1244,7 +1298,7 @@ class ZfsNode(ExecuteNode):
|
||||
|
||||
|
||||
def parse_zfs_progress(self, line, hide_errors, prefix):
|
||||
"""try to parse progress output of zfs recv -Pv, and dont show it as error to the user """
|
||||
"""try to parse progress output of zfs recv -Pv, and don't show it as error to the user """
|
||||
|
||||
#is it progress output?
|
||||
progress_fields=line.rstrip().split("\t")
|
||||
@ -1258,7 +1312,7 @@ class ZfsNode(ExecuteNode):
|
||||
#always output for debugging offcourse
|
||||
self.debug(prefix+line.rstrip())
|
||||
|
||||
#actual usefull info
|
||||
#actual useful info
|
||||
if len(progress_fields)>=3:
|
||||
if progress_fields[0]=='full' or progress_fields[0]=='size':
|
||||
self._progress_total_bytes=int(progress_fields[2])
|
||||
@ -1273,8 +1327,8 @@ class ZfsNode(ExecuteNode):
|
||||
bytes_left=self._progress_total_bytes-bytes
|
||||
minutes_left=int((bytes_left/(bytes/(time.time()-self._progress_start_time)))/60)
|
||||
|
||||
print(">>> {}% {}MB/s (total {}MB, {} minutes left) \r".format(percentage, speed, int(self._progress_total_bytes/(1024*1024)), minutes_left), end='')
|
||||
sys.stdout.flush()
|
||||
print(">>> {}% {}MB/s (total {}MB, {} minutes left) \r".format(percentage, speed, int(self._progress_total_bytes/(1024*1024)), minutes_left), end='', file=sys.stderr)
|
||||
sys.stderr.flush()
|
||||
|
||||
return
|
||||
|
||||
@ -1326,14 +1380,14 @@ class ZfsNode(ExecuteNode):
|
||||
|
||||
pools[pool].append(snapshot)
|
||||
|
||||
#add snapshot to cache (also usefull in testmode)
|
||||
#add snapshot to cache (also useful in testmode)
|
||||
dataset.snapshots.append(snapshot) #NOTE: this will trigger zfs list
|
||||
|
||||
if not pools:
|
||||
self.verbose("No changes anywhere: not creating snapshots.")
|
||||
return
|
||||
|
||||
#create consitent snapshot per pool
|
||||
#create consistent snapshot per pool
|
||||
for (pool_name, snapshots) in pools.items():
|
||||
cmd=[ "zfs", "snapshot" ]
|
||||
|
||||
@ -1350,6 +1404,9 @@ class ZfsNode(ExecuteNode):
|
||||
|
||||
returns: list of ZfsDataset
|
||||
"""
|
||||
|
||||
self.debug("Getting selected datasets")
|
||||
|
||||
#get all source filesystems that have the backup property
|
||||
lines=self.run(tab_split=True, readonly=True, cmd=[
|
||||
"zfs", "get", "-t", "volume,filesystem", "-o", "name,value,source", "-s", "local,inherited", "-H", "autobackup:"+self.backup_name
|
||||
@ -1385,11 +1442,6 @@ class ZfsNode(ExecuteNode):
|
||||
return(selected_filesystems)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
class ZfsAutobackup:
|
||||
"""main class"""
|
||||
def __init__(self):
|
||||
@ -1407,13 +1459,13 @@ class ZfsAutobackup:
|
||||
parser.add_argument('target_path', help='Target ZFS filesystem')
|
||||
|
||||
parser.add_argument('--other-snapshots', action='store_true', help='Send over other snapshots as well, not just the ones created by this tool.')
|
||||
parser.add_argument('--no-snapshot', action='store_true', help='Dont create new snapshots (usefull for finishing uncompleted backups, or cleanups)')
|
||||
parser.add_argument('--no-send', action='store_true', help='Dont send snapshots (usefull for cleanups, or if you want a serperate send-cronjob)')
|
||||
parser.add_argument('--min-change', type=int, default=200000, help='Number of bytes written after which we consider a dataset changed (default %(default)s)')
|
||||
parser.add_argument('--no-snapshot', action='store_true', help='Don\'t create new snapshots (useful for finishing uncompleted backups, or cleanups)')
|
||||
parser.add_argument('--no-send', action='store_true', help='Don\'t send snapshots (useful for cleanups, or if you want a serperate send-cronjob)')
|
||||
parser.add_argument('--min-change', type=int, default=1, help='Number of bytes written after which we consider a dataset changed (default %(default)s)')
|
||||
parser.add_argument('--allow-empty', action='store_true', help='If nothing has changed, still create empty snapshots. (same as --min-change=0)')
|
||||
parser.add_argument('--ignore-replicated', action='store_true', help='Ignore datasets that seem to be replicated some other way. (No changes since lastest snapshot. Usefull for proxmox HA replication)')
|
||||
parser.add_argument('--no-holds', action='store_true', help='Dont lock snapshots on the source. (Usefull to allow proxmox HA replication to switches nodes)')
|
||||
#not sure if this ever was usefull:
|
||||
parser.add_argument('--ignore-replicated', action='store_true', help='Ignore datasets that seem to be replicated some other way. (No changes since lastest snapshot. Useful for proxmox HA replication)')
|
||||
parser.add_argument('--no-holds', action='store_true', help='Don\'t lock snapshots on the source. (Useful to allow proxmox HA replication to switches nodes)')
|
||||
#not sure if this ever was useful:
|
||||
# parser.add_argument('--ignore-new', action='store_true', help='Ignore filesystem if there are already newer snapshots for it on the target (use with caution)')
|
||||
|
||||
parser.add_argument('--resume', action='store_true', help='Support resuming of interrupted transfers by using the zfs extensible_dataset feature (both zpools should have it enabled) Disadvantage is that you need to use zfs recv -A if another snapshot is created on the target during a receive. Otherwise it will keep failing.')
|
||||
@ -1424,10 +1476,11 @@ class ZfsAutobackup:
|
||||
# parser.add_argument('--destroy-stale', action='store_true', help='Destroy stale backups that have no more snapshots. Be sure to verify the output before using this! ')
|
||||
parser.add_argument('--clear-refreservation', action='store_true', help='Filter "refreservation" property. (recommended, safes space. same as --filter-properties refreservation)')
|
||||
parser.add_argument('--clear-mountpoint', action='store_true', help='Set property canmount=noauto for new datasets. (recommended, prevents mount conflicts. same as --set-properties canmount=noauto)')
|
||||
parser.add_argument('--filter-properties', type=str, help='List of propererties to "filter" when receiving filesystems. (you can still restore them with zfs inherit -S)')
|
||||
parser.add_argument('--filter-properties', type=str, help='List of properties to "filter" when receiving filesystems. (you can still restore them with zfs inherit -S)')
|
||||
parser.add_argument('--set-properties', type=str, help='List of propererties to override when receiving filesystems. (you can still restore them with zfs inherit -S)')
|
||||
parser.add_argument('--rollback', action='store_true', help='Rollback changes on the target before starting a backup. (normally you can prevent changes by setting the readonly property on the target_path to on)')
|
||||
parser.add_argument('--ignore-transfer-errors', action='store_true', help='Ignore transfer errors (still checks if received filesystem exists. usefull for acltype errors)')
|
||||
parser.add_argument('--rollback', action='store_true', help='Rollback changes to the latest target snapshot before starting. (normally you can prevent changes by setting the readonly property on the target_path to on)')
|
||||
parser.add_argument('--destroy-incompatible', action='store_true', help='Destroy incompatible snapshots on target. Use with care! (implies --rollback)')
|
||||
parser.add_argument('--ignore-transfer-errors', action='store_true', help='Ignore transfer errors (still checks if received filesystem exists. useful for acltype errors)')
|
||||
parser.add_argument('--raw', action='store_true', help='For encrypted datasets, send data exactly as it exists on disk.')
|
||||
|
||||
|
||||
@ -1435,13 +1488,16 @@ class ZfsAutobackup:
|
||||
parser.add_argument('--verbose', action='store_true', help='verbose output')
|
||||
parser.add_argument('--debug', action='store_true', help='Show zfs commands that are executed, stops after an exception.')
|
||||
parser.add_argument('--debug-output', action='store_true', help='Show zfs commands and their output/exit codes. (noisy)')
|
||||
parser.add_argument('--progress', action='store_true', help='show zfs progress output (to stderr)')
|
||||
parser.add_argument('--progress', action='store_true', help='show zfs progress output (to stderr). Enabled by default on ttys.')
|
||||
|
||||
#note args is the only global variable we use, since its a global readonly setting anyway
|
||||
args = parser.parse_args()
|
||||
|
||||
self.args=args
|
||||
|
||||
if sys.stderr.isatty():
|
||||
args.progress=True
|
||||
|
||||
if args.debug_output:
|
||||
args.debug=True
|
||||
|
||||
@ -1451,6 +1507,9 @@ class ZfsAutobackup:
|
||||
if args.allow_empty:
|
||||
args.min_change=0
|
||||
|
||||
if args.destroy_incompatible:
|
||||
args.rollback=True
|
||||
|
||||
self.log=Log(show_debug=self.args.debug, show_verbose=self.args.verbose)
|
||||
|
||||
|
||||
@ -1469,105 +1528,126 @@ class ZfsAutobackup:
|
||||
|
||||
def run(self):
|
||||
|
||||
self.verbose (HEADER)
|
||||
try:
|
||||
self.verbose (HEADER)
|
||||
|
||||
if self.args.test:
|
||||
self.verbose("TEST MODE - SIMULATING WITHOUT MAKING ANY CHANGES")
|
||||
if self.args.test:
|
||||
self.verbose("TEST MODE - SIMULATING WITHOUT MAKING ANY CHANGES")
|
||||
|
||||
self.set_title("Settings summary")
|
||||
self.set_title("Settings summary")
|
||||
|
||||
description="[Source]"
|
||||
source_thinner=Thinner(self.args.keep_source)
|
||||
source_node=ZfsNode(self.args.backup_name, self, ssh_config=self.args.ssh_config, ssh_to=self.args.ssh_source, readonly=self.args.test, debug_output=self.args.debug_output, description=description, thinner=source_thinner)
|
||||
source_node.verbose("Send all datasets that have 'autobackup:{}=true' or 'autobackup:{}=child'".format(self.args.backup_name, self.args.backup_name))
|
||||
description="[Source]"
|
||||
source_thinner=Thinner(self.args.keep_source)
|
||||
source_node=ZfsNode(self.args.backup_name, self, ssh_config=self.args.ssh_config, ssh_to=self.args.ssh_source, readonly=self.args.test, debug_output=self.args.debug_output, description=description, thinner=source_thinner)
|
||||
source_node.verbose("Send all datasets that have 'autobackup:{}=true' or 'autobackup:{}=child'".format(self.args.backup_name, self.args.backup_name))
|
||||
|
||||
self.verbose("")
|
||||
self.verbose("")
|
||||
|
||||
description="[Target]"
|
||||
target_thinner=Thinner(self.args.keep_target)
|
||||
target_node=ZfsNode(self.args.backup_name, self, ssh_config=self.args.ssh_config, ssh_to=self.args.ssh_target, readonly=self.args.test, debug_output=self.args.debug_output, description=description, thinner=target_thinner)
|
||||
target_node.verbose("Receive datasets under: {}".format(self.args.target_path))
|
||||
description="[Target]"
|
||||
target_thinner=Thinner(self.args.keep_target)
|
||||
target_node=ZfsNode(self.args.backup_name, self, ssh_config=self.args.ssh_config, ssh_to=self.args.ssh_target, readonly=self.args.test, debug_output=self.args.debug_output, description=description, thinner=target_thinner)
|
||||
target_node.verbose("Receive datasets under: {}".format(self.args.target_path))
|
||||
|
||||
self.set_title("Selecting")
|
||||
selected_source_datasets=source_node.selected_datasets
|
||||
if not selected_source_datasets:
|
||||
self.error("No source filesystems selected, please do a 'zfs set autobackup:{0}=true' on the source datasets you want to backup.".format(self.args.backup_name))
|
||||
|
||||
self.set_title("Selecting")
|
||||
selected_source_datasets=source_node.selected_datasets
|
||||
if not selected_source_datasets:
|
||||
self.error("No source filesystems selected, please do a 'zfs set autobackup:{0}=true' on the source datasets you want to backup.".format(self.args.backup_name))
|
||||
return(255)
|
||||
|
||||
source_datasets=[]
|
||||
|
||||
|
||||
#filter out already replicated stuff?
|
||||
if not self.args.ignore_replicated:
|
||||
source_datasets=selected_source_datasets
|
||||
else:
|
||||
self.set_title("Filtering already replicated filesystems")
|
||||
for selected_source_dataset in selected_source_datasets:
|
||||
if selected_source_dataset.is_changed(self.args.min_change):
|
||||
source_datasets.append(selected_source_dataset)
|
||||
else:
|
||||
selected_source_dataset.verbose("Ignoring, already replicated")
|
||||
|
||||
|
||||
if not self.args.no_snapshot:
|
||||
self.set_title("Snapshotting")
|
||||
source_node.consistent_snapshot(source_datasets, source_node.new_snapshotname(), min_changed_bytes=self.args.min_change)
|
||||
|
||||
|
||||
if self.args.no_send:
|
||||
self.set_title("Thinning")
|
||||
else:
|
||||
self.set_title("Sending and thinning")
|
||||
|
||||
if self.args.filter_properties:
|
||||
filter_properties=self.args.filter_properties.split(",")
|
||||
else:
|
||||
filter_properties=[]
|
||||
|
||||
if self.args.set_properties:
|
||||
set_properties=self.args.set_properties.split(",")
|
||||
else:
|
||||
set_properties=[]
|
||||
|
||||
if self.args.clear_refreservation:
|
||||
filter_properties.append("refreservation")
|
||||
|
||||
if self.args.clear_mountpoint:
|
||||
set_properties.append("canmount=noauto")
|
||||
|
||||
#sync datasets
|
||||
fail_count=0
|
||||
target_datasets=[]
|
||||
for source_dataset in source_datasets:
|
||||
|
||||
try:
|
||||
#determine corresponding target_dataset
|
||||
target_name=self.args.target_path + "/" + source_dataset.lstrip_path(self.args.strip_path)
|
||||
target_dataset=ZfsDataset(target_node, target_name)
|
||||
target_datasets.append(target_dataset)
|
||||
|
||||
#ensure parents exists
|
||||
if not self.args.no_send and not target_dataset.parent.exists:
|
||||
target_dataset.parent.create_filesystem(parents=True)
|
||||
|
||||
source_dataset.sync_snapshots(target_dataset, show_progress=self.args.progress, resume=self.args.resume, filter_properties=filter_properties, set_properties=set_properties, ignore_recv_exit_code=self.args.ignore_transfer_errors, source_holds= not self.args.no_holds, rollback=self.args.rollback, raw=self.args.raw, other_snapshots=self.args.other_snapshots, no_send=self.args.no_send, destroy_incompatible=self.args.destroy_incompatible)
|
||||
except Exception as e:
|
||||
fail_count=fail_count+1
|
||||
self.error("DATASET FAILED: "+str(e))
|
||||
if self.args.debug:
|
||||
raise
|
||||
|
||||
#also thin target_datasets that are not on the source any more
|
||||
self.debug("Thinning obsolete datasets")
|
||||
for dataset in ZfsDataset(target_node, self.args.target_path).recursive_datasets:
|
||||
if dataset not in target_datasets:
|
||||
dataset.verbose("Missing on source")
|
||||
dataset.thin()
|
||||
|
||||
|
||||
if not fail_count:
|
||||
if self.args.test:
|
||||
self.set_title("All tests successfull.")
|
||||
else:
|
||||
self.set_title("All backups completed successfully")
|
||||
else:
|
||||
self.error("{} datasets failed!".format(fail_count))
|
||||
|
||||
if self.args.test:
|
||||
self.verbose("TEST MODE - DID NOT MAKE ANY BACKUPS!")
|
||||
|
||||
return(fail_count)
|
||||
|
||||
except Exception as e:
|
||||
self.error("Exception: "+str(e))
|
||||
if self.args.debug:
|
||||
raise
|
||||
return(255)
|
||||
except KeyboardInterrupt as e:
|
||||
self.error("Aborted")
|
||||
return(255)
|
||||
|
||||
source_datasets=[]
|
||||
|
||||
#filter out already replicated stuff?
|
||||
if not self.args.ignore_replicated:
|
||||
source_datasets=selected_source_datasets
|
||||
else:
|
||||
self.set_title("Filtering already replicated filesystems")
|
||||
for selected_source_dataset in selected_source_datasets:
|
||||
if selected_source_dataset.is_changed(self.args.min_change):
|
||||
source_datasets.append(selected_source_dataset)
|
||||
else:
|
||||
selected_source_dataset.verbose("Ignoring, already replicated")
|
||||
|
||||
|
||||
if not self.args.no_snapshot:
|
||||
self.set_title("Snapshotting")
|
||||
source_node.consistent_snapshot(source_datasets, source_node.new_snapshotname(), min_changed_bytes=self.args.min_change)
|
||||
|
||||
|
||||
|
||||
if self.args.no_send:
|
||||
self.set_title("Thinning")
|
||||
else:
|
||||
self.set_title("Sending and thinning")
|
||||
|
||||
if self.args.filter_properties:
|
||||
filter_properties=self.args.filter_properties.split(",")
|
||||
else:
|
||||
filter_properties=[]
|
||||
|
||||
if self.args.set_properties:
|
||||
set_properties=self.args.set_properties.split(",")
|
||||
else:
|
||||
set_properties=[]
|
||||
|
||||
if self.args.clear_refreservation:
|
||||
filter_properties.append("refreservation")
|
||||
|
||||
if self.args.clear_mountpoint:
|
||||
set_properties.append("canmount=noauto")
|
||||
|
||||
fail_count=0
|
||||
for source_dataset in source_datasets:
|
||||
|
||||
try:
|
||||
#determine corresponding target_dataset
|
||||
target_name=self.args.target_path + "/" + source_dataset.lstrip_path(self.args.strip_path)
|
||||
target_dataset=ZfsDataset(target_node, target_name)
|
||||
|
||||
#ensure parents exists
|
||||
if not self.args.no_send and not target_dataset.parent.exists:
|
||||
target_dataset.parent.create_filesystem(parents=True)
|
||||
|
||||
source_dataset.sync_snapshots(target_dataset, show_progress=self.args.progress, resume=self.args.resume, filter_properties=filter_properties, set_properties=set_properties, ignore_recv_exit_code=self.args.ignore_transfer_errors, source_holds= not self.args.no_holds, rollback=self.args.rollback, raw=self.args.raw, other_snapshots=self.args.other_snapshots, no_send=self.args.no_send)
|
||||
except Exception as e:
|
||||
fail_count=fail_count+1
|
||||
source_dataset.error("DATASET FAILED: "+str(e))
|
||||
if self.args.debug:
|
||||
raise
|
||||
|
||||
|
||||
|
||||
if not fail_count:
|
||||
if self.args.test:
|
||||
self.set_title("All tests successfull.")
|
||||
else:
|
||||
self.set_title("All backups completed succesfully")
|
||||
else:
|
||||
self.error("{} datasets failed!".format(fail_count))
|
||||
|
||||
if self.args.test:
|
||||
self.verbose("TEST MODE - DID NOT MAKE ANY BACKUPS!")
|
||||
|
||||
return(fail_count)
|
||||
|
||||
if __name__ == "__main__":
|
||||
zfs_autobackup=ZfsAutobackup()
|
||||
|
||||
BIN
doc/thinner.odg
Normal file
BIN
doc/thinner.odg
Normal file
Binary file not shown.
BIN
doc/thinner.png
Normal file
BIN
doc/thinner.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 22 KiB |
Reference in New Issue
Block a user